Numpy 03_ 배열 재형성, indexing, 배열 복사, 배열 데이터 다루기

1. Numpy 배열 재형성
1) reshape
- 배열의 shape(크기) 를 변경한다.
- Numpy에서 배열의 차원을 재구조화, 변경하고자 할 때 사용한다.
- 요소의 개수는 동일해야 한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
import numpy as np
t_array = np.arange(1,9)
print("t_array 출력")
print(t_array)
print("\nt_array의 shape 출력")
print(t_array.shape)
print("\n2by4로 재배열하기")
a = t_array.reshape(2,4)
print(a.shape)
|
cs |

이때, reshape의 첫번째 인자에 -1을 넣으면 요소의 개수와 열의 개수에 따라 행이 자동으로 정해진다.
예를 들어, 요소가 총 8개인 a를 -1,4로 재배열하면 a.reshape(-1,4) 열의 개수인 4개씩 총 2행이어야 8개의 요소가 되므로 행의 개수는 2개이다.. 따라서 a.reshape(-1,4) 는 2by4 배열이 된다.
|
1
2
3
4
|
import numpy as np
a.reshape(-1,4)
|
cs |

3차원 배열 a.reshape(-1,2,2)의 결과는 다음과 같다.
|
1
2
3
4
|
import numpy as np
a.reshape(-1,2,2)
|
cs |

2) 평탄화
- 다차원 배열을 낮은 차원으로 변환한다.
① ravel
- 다차원 배열을 1차원 배열로 평탄화해주는 numpy 함수
- ravel은 원본의 뷰를 반환하며, 주의할 점은 ravel로 반환된 데이터를 수정하면 원본 데이터도 수정된다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
import numpy as np
b = np.arange(1,9).reshape(2,2,2)
print("b 출력")
print(b)
print("\nravel 함수를 사용해서 1차원으로 평탄화하기")
c = b.ravel()
print(c)
print("\nravel 로 반환된 데이터 수정")
c[3] = 10
print(c)
print("\n원본데이터 b 확인하기")
print(b)
|
cs |

② flatten
- flatten은 원본의 복사본을 반환한다.
- ravel과는 다르게 반환된 데이터를 수정하여도 원본데이터는 변하지 않는다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
import numpy as np
b = np.arange(1,9).reshape(2,2,2)
print("b 출력")
print(b)
print("\nflatten 함수를 사용해서 1차원으로 평탄화하기")
c = b.flatten()
print(c)
print("\nflatten 으로 반환된 데이터 수정")
c[3] = 10
print(c)
print("\n원본데이터 b 확인하기")
print(b)
|
cs |

3) 전치
- 행렬의 행과 열을 서로 바꾼다.
- transpose() 또는 T 를 사용한다.
- 이때, 원본데이터는 변형되지 않는다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import numpy as np
a = np.arange(1,7).reshape(3,2)
print("a 출력")
print(a)
print("\n3by2에서 2by3으로 전치 ; transpose() 사용")
print(a.transpose())
print("\n3by2에서 2by3으로 전치 ; T 사용")
print(a.T)
print("\n원본 데이터 확인")
print(a)
|
cs |

4) 배열 결합
① concatenate()
- 배열과 배열을 결합하는 함수
- axis 기준으로 결합
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import numpy as np
a = np.arange(1,4).reshape(1,3)
print("a 출력")
print(a)
b = np.arange(4,7).reshape(1,3)
print("\nb 출력")
print(b)
print("\nconcatenate를 사용하여 a와 b를 axis = 0(세로 방향)으로 결합하기")
print(np.concatenate((a,b), axis = 0))
print("\nconcatenate를 사용하여 a와 b를 axis = 1(가로 방향)으로 결합하기")
print(np.concatenate((a,b), axis = 1))
|
cs |

② vstack(), hstack()
- vstack() : 수직 방향으로 결합 ( np.concatenate(data, axis = 0) 과 동일하다.)
- hstack() : 수평 방향으로 결합 ( np.concatenate(data, axis = 1) 과 동일하다.)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import numpy as np
a = np.arange(1,4).reshape(1,3)
print("a 출력")
print(a)
b = np.arange(4,7).reshape(1,3)
print("\nb 출력")
print(b)
print("\nvstack 함수를 사용하여 a와 b를 axis = 0(세로 방향)으로 결합하기")
print(np.vstack((a,b)))
print("\nhstack 함수를 사용하여 a와 b를 axis = 1(가로 방향)으로 결합하기")
print(np.hstack((a,b)))
|
cs |

5) 배열 분리
① np.split(), vsplit(), hsplit()
- np.split(data, 나누는 배열 개수) : 주어진 개수만큼 동일한 크기로 배열을 분할한다.
|
1
2
3
4
5
6
7
8
9
10
11
|
import numpy as np
a = np.arange(1,17).reshape(4,4)
print("a 출력")
print(a)
print("\nnp.split() 을 사용해서 배열을 2개의 배열로 분할")
print(np.split(a,2))
print("\n4by4 배열을 3개로 분할하기; error")
print(np.split(a,3))
|
cs |
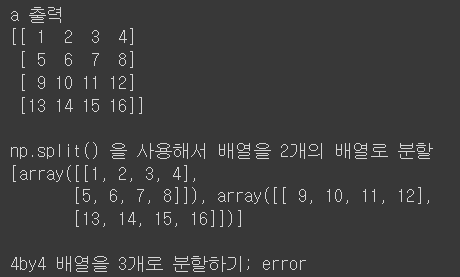
위처럼 np.split()을 사용할 때는 나누는 배열의 개수를 잘 설정해야 한다.
위의 경우에는 16개의 요소를 동일한 크기(shape)로 나눠야 하므로 1,2,4만 가능하다.
만일 3개로 분할한다면 error가 생긴다.
이를 3개로 분할하고 싶다면, 다음과 같이 코드를 작성하면 하위 배열의 크기가 다르게 3개로 분할가능하다.
|
1
2
3
4
|
import numpy as np
a = np.arange(1,17).reshape(4,4)
np.array_split(a,3)
|
cs |

- vsplit() : 배열을 수직 방향으로 분할하는 함수
- hsplit() : 배열을 수평방향으로 분할하는 함수
수직방향의 분할과 수평방향의 분할이 헷갈릴 수도 있다.
이때의 방향이란 화살표를 생각하면 된다.
"수직 방향"으로 분할하는 vsplit 함수는 2차원 배열에서 axis = 0을 기준으로 split한다
즉 ,
↓
↓
↓
↓
수직방향으로 내려가면서 배열을 분할해나가는 것이다.
예시 코드를 보면서 이해해보자.
|
1
2
3
4
5
6
7
8
|
import numpy as np
a = np.arange(1,21).reshape(4,5)
print("a 출력")
print(a)
print("\nvsplit 사용")
print(np.vsplit(a,2))
|
cs |

즉, 분할해나가는 방향이 수직방향인 것이지, 분할하는 기준선이 수직방향이라는 것이 아니다.
반대로, 수평방향으로 분할하는 hsplit 함수는 2차원 배열에서 axis = 1을 기준으로 split한다
즉, →→→→ 오른쪽 수평방향으로 이동하면서 배열을 분할해나간다.
예제는 다음과 같다.
|
1
2
3
4
5
6
7
8
|
import numpy as np
a = np.arange(1,25).reshape(4,6)
print("a 출력")
print(a)
print("\nhsplit 사용")
print(np.hsplit(a,2))
|
cs |

2. Numpy 색인(indexing)
1) 색인(indexing)
- 배열의 각 요소는 axis 인덱스 배열로 참조할 수 있다.
- 1차원 배열은 1개의 인덱스, 2차원 배열은 2개의 인덱스, n차원 배열은 n개의 인덱스 요소로 참조가 가능하다.
<1차원 배열>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import numpy as np
a = np.arange(1,5)
print("a 출력")
print(a)
print("\n1차원 배열")
print("a의 0번 index 요소 출력:")
print(a[0])
print("a의 0~1번 index 요소 출력:")
print(a[0:2])
print("a의 모든 요소 출력:")
print(a[:])
print("a의 0~2번 index 요소 출력:")
print(a[:3])
|
cs |

<2차원 배열>
: 2차원 배열의 indexing에서 앞의 인자는 행의 index, 뒤의 인자는 열의 index이다.
이때, 배열[행의 index, 열의 index] 형식과 배열[행의 index][열의 index] 형식은 동일한 결과이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
import numpy as np
a = np.arange(1,5)
b = a.reshape(2,2)
print("b 출력")
print(b)
print("\n2차원 배열")
print("b의 0번 행, 0번 열의 요소 출력:")
print(b[0,0])
print(b[0][0])
print("b의 0번 행, 1번 열의 요소 출력:")
print(b[0,1])
|
cs |

<3차원 배열>
: 3차원 배열의 indexing에서 첫번째 인자는 깊이의 index, 두번째 인자는 행의 index, 세번째 인자는 열의 index이다.
이때, 배열[깊이의 index, 행의 index, 열의 index] 형식과 배열[깊이의 index][행의 index][열의 index] 형식은 동일한 결과이다.
|
1
2
3
4
5
6
7
8
9
10
|
import numpy as np
a = np.arange(1,5)
c = np.arange(1,28).reshape(3,3,3)
print("c 출력")
print(c)
print("\n3차원 배열")
print("c의 1번 index 깊이, 2번 index 행, 0번 index 열의 요소 출력:")
print(c[1,2,0])
|
cs |

+인덱스를 사용해서 배열요소에 값 할당
|
1
2
3
4
5
6
7
8
9
|
import numpy as np
a = np.arange(1,5).reshape(2,2)
print("a 출력")
print(a)
print("\n0번 index 행, 1번 index 열의 요소에 5를 할당")
a[0,1] = 5
print(a)
|
cs |

2) 슬라이스 색인(Slicing)
- 여러 개의 배열 요소를 참조할 때 슬라이싱(slicing)을 사용한다.
- 다차원 객체는 하나 이상의 축(axis) 을 기준으로 슬라이싱한다.
- 슬라이싱의 경우 끝의 index는 포함하지 않는다.
<2차원 배열>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import numpy as np
a = np.arange(1,21).reshape(4,5)
print("a 출력")
print(a)
print("\n전체 행, 3번index 열부터 마지막 열까지")
print(a[:, 3:])
print("\n슬라이싱의 경우 끝을 포함하지 않는다.")
print(a[1, 2:4])
print("\n전체 행, 2번 index 열부터 3번 인덱스 열까지 2개 index 간격으로(2 열) 추출")
print(a[:, 2:4:2])
print("\n전체 행, 첫번째 열부터 마지막 열까지 2개 index 간격으로(0, 2, 4열) 추출")
print(a[:, ::2])
|
cs |

<3차원 배열>
|
1
2
3
4
5
6
7
8
|
import numpy as np
a = np.arange(1,65).reshape(4,4,4)
print("a 출력")
print(a)
print("\n2번 index 깊이, 0~1행, 0,2 열")
print(a[2,0:2, ::2])
|
cs |

3) boolean indexing
- 조건에 대해서 배열 각 요소가 True/False인지 판정하고 해당 index의 값만 추출하는 방법
- 기본 인덱싱에서는 괄호 안에 숫자가 들어간 것에 반해, boolean indexing 은 괄호 안에 조건이 들어간다.
- 단, 조건은 하나만 가능하며, 두 개 이상의 조건을 사용하기 위해서는 괄호 안에 np.logical_and(조건1, 조건2) / np.logical_or(조건1, 조건2) 의 형식으로 작성해준다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import numpy as np
a = np.arange(1,21).reshape(4,5)
print("a 출력")
print(a)
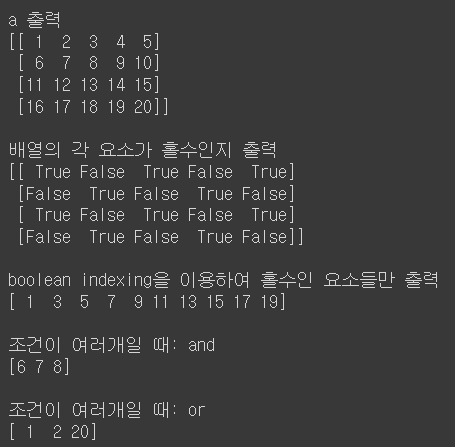
print("\n배열의 각 요소가 홀수인지 출력")
print(a%2 == 1)
print("\nboolean indexing을 이용하여 홀수인 요소들만 출력")
print(a[a%2 ==1])
print("\n조건이 여러개일 때: and")
print(a[np.logical_and(a > 5, a < 9)])
print("\n조건이 여러개일 때: or")
print(a[np.logical_or(a < 3, a > 19)])
|
cs |
4) fancy indexing
- 정수 배열을 사용한 색인을 설명하기 위해 Numpy 에서 차용한 단어
- ndarray를 index value 로 사용하여 값을 추출함
- index로 사용할 array는 반드시 integer로 선언해야 한다.
- 괄호 안에 선언한 배열이 들어간다.
- 다차원 배열의 경우, 깊이 배열, 행 배열, 열 배열을 따로 선언하여 사용한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
import numpy as np
print("<1차원 배열>")
arr_1d = np.arange(1,7)
print("\narr_1d 출력")
print(arr_1d)
print("\nindex로 사용할 array 선언")
arr_a = np.array([3,1,2,0,1,5], int)
print(arr_b)
print("\narr_a index에 맞는 arr_1d의 값 출력")
print(arr_1d[arr_a])
print("\n\n<2차원 배열>")
arr_2d = np.arange(1,13).reshape(4,3)
print("\narr_2d 출력")
print(arr_2d)
print("\nindex로 사용할 array 선언")
arr_a = np.array([3,1,2,0,1,2], int)
arr_b = np.array([1,0,2,0,2,1], int)
print("행 인덱스 arr_a 출력")
print(arr_a)
print("열 인덱스 arr_b 출력")
print(arr_b)
print("\narr_a 를 행 index, arr_b를 열 index로 하여 arr_2d 배열 fancy slicing")
print(arr_2d[arr_a, arr_b])
|
cs |

5) argmax, argmin
- array내의 최댓값 또는 최솟값의 인덱스를 반환한다.
|
1
2
3
4
5
6
7
8
9
10
11
|
import numpy as np
a = np.array([4,1,5,0,8,12,0,18])
print("a 출력")
print(a)
print("\narray 내의 최대값의 index 출력: argmax")
print(np.argmax(a))
print("\narray 내의 최소값의 index 출력: argmin")
print(np.argmin(a))
|
cs |

+ numpy.random.choice(a, size = None, replace=True, p=None)
- a : 1차원 배열 혹은 정수(정수인 경우, np.arange(a)와 같은 배열 생성)
- size : 정수 혹은 튜플(튜플인 경우, 행렬로 리턴됨. (m,n,k) -> m*n*k), optional
- replace : 중복 허용 여부, boolean, optional
- p : 1차원 배열, 각 데이터가 선택될 확률, optional
|
1
2
3
4
5
6
7
8
9
10
|
import numpy as np
print("0이상 5 미만인 정수 중 3개를 출력, +중복을 허용")
print(np.random.choice(5, 3, True))
print("\n2 이상 22 미만의 정수 중에서 12개를 출력, 3*4 행렬로 재배열")
print(np.random.choice(np.arange(2,22), 12).reshape(3,4))
print("\n1이상 21 미만의 정수 중에서 2*2 튜플 출력, +중복을 허용")
print(np.random.choice(np.arange(1,21), (2,2), True))
|
cs |

- 이때, axis = 0 인자를 사용하면 세로축 요소들끼리 비교한 각 열의 최댓값/최솟값의 인덱스가 출력되고
axis = 1 인자를 사용하면 가로축 요소들끼리 비교한 각 행의 최댓값/최솟값의 인덱스가 출력된다.
|
1
2
3
4
5
6
7
8
9
10
11
|
import numpy as np
arr_2d = np.random.choice(np.arange(1, 30), 15).reshape(3,5)
print("arr_2d 출력")
print(arr_2d)
print("\n각 열의 최댓값의 인덱스 출력: argmax, axis = 0")
print(np.argmax(arr_2d, axis = 0))
print("\n각 행의 최솟값의 인덱스 출력: argmin, axis = 1")
print(np.argmin(arr_2d, axis = 1))
|
cs |

3. 배열 복사 : copy()
- ndarray 배열 객체에 대한 slice, indexing이 반환하는 배열은 새로운 객체가 아닌 기존 배열의 뷰(view)이다.
- 즉, 반환된 배열의 값을 변경하면 원본 배열에 반영된다.
- 기본 배열로부터 새로운 배열을 생성하기 위해서는 copy 함수를 통해 명시적으로 사용해야 한다.
- 원본 배열과 copy 함수로 복사된 사본 배열은 완전히 다른 별도의 객체이다.
*c.f.) 뷰란?
뷰는 사용자에게 접근이 허용된 자료만을 제한적으로 보여주기 위해 하나 이상의 기본 테이블로부터 유도된, 이름을 가지는 가상 테이블이다.
뷰는 저장장치 내에 물리적으로 존재하지 않지만 사용자에게 있는 것처럼 간주된다.
뷰는 데이터 보정작업, 처리과정 시험 등 임시적인 작업을 위한 용도로 활용된다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import numpy as np
a1 = np.arange(1,21).reshape(4,5)
print("a1 출력")
print(a1)
a2 = np.copy(a1[:, :2])
print("\na2 출력")
print(a2)
print("\na2의 값 변경")
a2[0,1] = 3
print(a2)
print("\na1의 값 확인")
print(a1)
|
cs |

4. 배열 데이터 다루기
1) resize
- reshape 와 같이 shape를 변경한다.
- 단, reshape는 배열의 요소 수를 변경할 수 없으나, resize는 변경 가능하다.
- reshape는 원본을 변형시키나, resize는 원본을 변형시키지 않는다.
: a1을 reshape한 b1을 생성할 경우, a1과 b1은 이름만 다를 뿐 같은 메모리 공간을 공유한다. 따라서 b1의 일부 요소를 변경한다면 원본인 a1은 변경된다.
그러나, a1을 resize한 b1을 생성할 경우, reshape와 달리 b1을 새로운 공간을 만들어 저장한다. 따라서 b1의 일부 요소를 변경하더라도 원본인 a1은 변경되지 않는다.
<reshape>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import numpy as np
a1 = np.arange(1,13).reshape(2,6)
print("초기 a1 출력")
print(a1)
print("\nreshape 사용")
print(np.reshape(a1, (3,4)))
print("\na1 출력; 원본 변경 여부 확인")
print(a1)
print("\n요수 수가 12개인 a1을 3*3 요소 수 9개인 배열로 변경 ; 불가능")
print(a1.reshape(3,3))
|
cs |

<resize>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
import numpy as np
a1 = np.arange(1,13).reshape(2,6)
print("초기 a1 출력")
print(a1)
print("\nresize 사용")
print(np.resize(a1, (6,2)))
print("\na1 출력; 원본 변경 여부 확인")
print(a1)
print("\na1 출력: 앞의 변수를 객체로 해서 사용했을 때 원본 변경 여부 확인")
a1.resize((6,2))
print(a1)
print("\n요수 수가 12개인 a1을 3*3 요소 수 9개인 배열로 변경 ; 가능")
print(np.resize(a1, (3,3)))
print("\n요수 수가 12개인 a1을 3*5 요소 수 15개인 배열로 변경 ; 불가능")
print(np.resize(a1, (3,5)))
|
cs |

++ 참고로, reshape의 경우에는 a1.reshape()로 하더라도 a1 원본은 변경되지 않는다.
2) append()
- 배열의 끝에 값을 추가한다.
<1차원>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import numpy as np
print("list")
arr = []
arr.append([1,2,3])
print("\narr 출력")
print(arr)
print("arr의 type")
print(type(arr))
print("\nNumpy로 생성한 array에 사용한 append()")
arr2 = np.array([])
arr2 = np.append(arr2, np.array([1,2,3]))
print("\narr2 출력")
print(arr2)
print("arr2의 type")
print(type(arr2))
|
cs |

<2차원>
|
1
2
3
4
5
6
7
8
9
10
11
12
|
import numpy as np
print("Numpy로 생성한 array에 사용한 append(); 2차원")
arr = np.empty((0,3), int)
print("\narr 출력")
print(arr)
print("\nappend 하기")
arr = np.append(arr, np.array([[1,2,3]]), axis = 0)
arr = np.append(arr, np.array([[4,5,6]]), axis = 0)
print("\narr 출력")
print(arr)
|
cs |

그렇다면, 비어있는 배열이 아니라 기존 2차원 배열에 값을 append한다면 어떻게 될까?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import numpy as np
a1 = np.arange(1,7).reshape(2,3)
print("a1 출력")
print(a1)
print("\na1에 한개의 값 append")
print(np.append(a1,3))
print("\naxis = 0을 기준으로 2차원 배열 추가 = 행추가")
print(np.append(a1, [[7,8,9]], axis = 0))
print("\naxis = 1을 기준으로 2차원 배열 추가 = 열추가")
print(np.append(a1, [[7], [8]], axis = 1))
|
cs |

이처럼 기존 2차원 배열 a1에 하나의 값 3을 append하면 1차원 배열으로 추가된다.
3) insert()
- 원하는 인덱스 위치에 데이터를 추가한다.
- 형식: insert(array, index, 값)
- np.insert를 사용하더라도 원본은 변형되지 않는다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import numpy as np
a = np.arange(1,10).reshape(3,3)
print("a 출력")
print(a)
print("\n1차원 배열로 값 추가")
print(np.insert(a,1,100))
print("\n2차원 배열로 값 추가 ; axis = 0")
print(np.insert(a,1,100, axis = 0))
print("\n2차원 배열로 값 추가 ; axis = 1")
print(np.insert(a,1,100, axis = 1))
print("\n원본 변형 여부 확인")
print(a)
|
cs |

4) delete()
- 원하는 인덱스 위치의 데이터를 삭제한다.
- 원본을 변형시키지 않는다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import numpy as np
a = np.arange(1,10).reshape(3,3)
print("초기 a 출력")
print(a)
print("\n1차원 배열로 변환한 후 2번째 index 위치의 데이터 삭제")
print(np.delete(a,2))
print("\n2차원 배열에서 행 삭제 : axis = 0")
print(np.delete(a, 2, axis = 0))
print("\n2차원 배열에서 열 삭제 : axis = 1")
print(np.delete(a, 2, axis = 1))
print("\n원본 변형 여부 확인 : a 출력")
print(a)
|
cs |
