인공지능/머신러닝
편향과 분산
eun_coco
2023. 1. 6. 23:48
"예측값들과 정답이 대체로 멀리 떨어져 있으면 결과의 편향(bias)가 높다고 말하고,
예측값들이 자기들끼리 대체로 멀리 흩어져있으면 결과의 분산(variance)가 높다고 말한다."

(1,1) 그림 : 예측값과 정답이 가까움(low bias), 예측값들끼리 가까움(low variance)
(1,2) 그림 : 예측값과 정답이 가까움(low bias), 예측값들끼리 멀리 흩어짐(high variance)
(2,1) 그림 : 예측값과 정답이 멀리 떨어짐(high bias), 예측값들끼리 가까움(low variance)
(2,2) 그림 : 예측값과 정답이 멀리 떨어짐(high bias), 예측값들끼리 가까움(high variance)

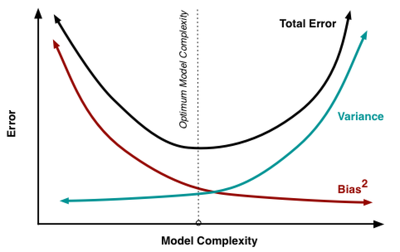
< Model Complexity가 낮음 = Simple >
왼쪽 그림
예측값과 정답이 멀리 떨어져있으므로 high bias, 예측값끼리 거리가 가까우므로 low variance
< Model Complexity가 높음 = Complex >
오른쪽 그림
예측값과 정답이 가까우므로 low bias, 예측값끼리 멀리 떨어져있으므로 high variance
이것을 편향과 분산 Trade-off, Bias Variance Trade-off 라고 함.