⛄ 텍스트 전처리의 개념
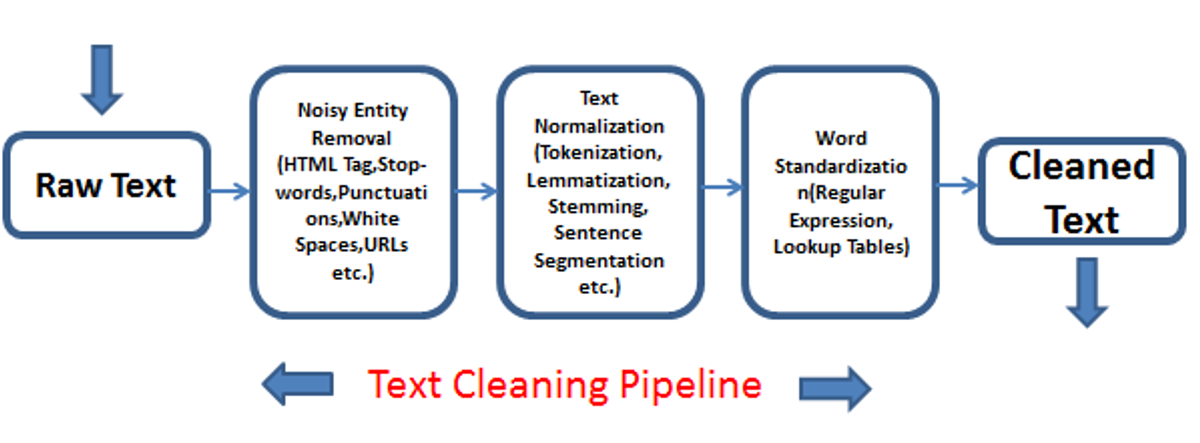
자연어 처리는
- 자연어로 쓰여진 글을 전처리하는 준비단계
- 전처리된 결과를 컴퓨터가 다루고 이해할 수 있는 형태로 변환하는 단계
- 변환된 형태를 이용해 다양한 분석을 수행하는 단계
로 나누어 생각할 수 있다.
⛄ 전처리의 단계
텍스트 전처리(Text Preprocessing)는
1) 주어진 텍스트에서 노이즈와 같이 불필요한 부분을 제거하고, 2) 문장을 표준 단어들로 분리한 후에, 3) 각 단어의 품사를 파악하는 것’까지를 의미한다
이를 정리하면 다음과 같습니다.
✔ 정제(cleaning) : 분석에 불필요한 노이즈를 제거(noise removal)하는 작업
✔ 토큰화(tokenization) : 주어진 텍스트를 원하는 단위(토큰, token)로 나누는 작업.
✔ 정규화 : 같은 의미를 가진 동일한 단어임에도 불구하고 다른 형태로 쓰여진 단어들을 통일시켜서 표준 단어로 만드는 작업
✔ 품사 태깅 : 품사 태깅은 앞서 토큰화한 단어에 대해 품사를 파악해 부착하는 것을 의미한다.
⛄ 토큰화 _ NLTK 실습
NLTK 는 교육용으로 개발된 자연어 처리 및 문서 분석용 파이썬 패키지로, WordNet을 비롯해 자연어 처리를 지원하는 다양한 라이브러리와 문서(말뭉치) 그리고 예제들을 제공한다.
말뭉치란?
말뭉치는 ‘언어 연구를 위해 컴퓨터가 텍스트를 가공, 처리, 분석할 수 있는 형태로 모아놓은 자료의 집합’
혹은 ‘자연언어 연구를 위해 특정한 목적으로 가지고 언어의 표본을 추출한 집합’이라고 정의한다.
즉, 자연어 처리나 텍스트 마이닝을 위해 유사한 문서들을 모아 놓은 집합이라고 할 수 있다.
NLTK 실습을 진행하기 위해 아래 코드를 코랩에서 실행한다. 코랩에는 NLTK가 내장되어 있으니 바로 임포트 할 수 있다.
#NLTK 실습
#필요한 NLTK library download
import nltk
nltk.download('punkt')
nltk.download('webtext')
nltk.download('wordnet')
nltk.download('stopwords')
nltk.download('averaged_perceptron_tagger')
nltk.download('omw-1.4')
nltk.download('tagsets')
토큰화는 주어진 텍스트를 원하는 단위로 나누는 작업을 말한다.
원하는 단위에 따라 아래의 종류가 있다.
1) 문장 토큰화
문장 토큰화는 여러 문장으로 이루어진 텍스트를 각 문장으로 나누는 것으로 NLTK의 sent_tokenize를 사용한다.
#문장 토큰화
para = "Hello everyone. It's good to see you. Let's start our text mining class!"
from nltk.tokenize import sent_tokenize
#주어진 text를 sentence 단위로 tokenize 함. 주로 . ! ? 등을 이용
print(sent_tokenize(para))
✨ 실행결과
['Hello everyone.', "It's good to see you.", "Let's start our text mining class!"]
내부적으로 sent_tokenize 는 영어 학습 데이터에 대해 사전학습된 모델을 사용해 토큰화한다.
다른 언어에 대해서는 다음과 같이 사전학습된 모델을 지정해서 실행할 수 있다.
#영어가 아닌 언어로 문장 토큰화
paragraph_french = """Je t'ai demandé si tu m'aimais bien, Tu m'a répondu non.
Je t'ai demandé si j'étais jolie, Tu m'a répondu non.
Je t'ai demandé si j'étai dans ton coeur, Tu m'a répondu non."""
import nltk.data
tokenizer = nltk.data.load('tokenizers/punkt/french.pickle')
print(tokenizer.tokenize(paragraph_french))
✨ 실행결과
["Je t'ai demandé si tu m'aimais bien, Tu m'a répondu non.", "Je t'ai demandé si j'étais jolie, Tu m'a répondu non.", "Je t'ai demandé si j'étai dans ton coeur, Tu m'a répondu non."]
NLTK에는 한글에 대해 사전학습된 모델은 아직 없다. 그러나 문장 토큰화는 각 문장의 끝에 있는 마침표 등을 기준으로 분리하도록 학습되어 있으므로, 한국어에 대해서도 어느정도 작동될 수 있다.
#한글 텍스트 문장 토큰화
para_kor = "안녕하세요, 여러분. 만나서 반갑습니다. 이제 텍스트마이닝 클래스를 시작해봅시다!"
#한국어에 대해서도 sentence tokenizer 는 잘 동작함
print(sent_tokenize(para_kor))
✨ 실행결과
['안녕하세요, 여러분.', '만나서 반갑습니다.', '이제 텍스트마이닝 클래스를 시작해봅시다!']
2) 단어 토큰화
일반적으로 토큰화라고 하면 단어 토큰화(word tokenize)를 의미한다.
NLTK에서는 word_tokenize와 WorkdPunctTokenizer를 사용해서 단어 토큰화를 할 수 있다.
- word_tokenize 사용
#단어 토큰화
from nltk.tokenize import word_tokenize
#주어진 text를 word 단위로 tokenize 함
print(word_tokenize(para))
✨ 실행결과
['Hello', 'everyone', '.', 'It', "'s", 'good', 'to', 'see', 'you', '.', 'Let', "'s", 'start', 'our', 'text', 'mining', 'class', '!']
#단어 토큰화 : WordPunctTokenizer 사용
from nltk.tokenize import WordPunctTokenizer
print(WordPunctTokenizer().tokenize(para))
✨ 실행결과
['Hello', 'everyone', '.', 'It', "'", 's', 'good', 'to', 'see', 'you', '.', 'Let', "'", 's', 'start', 'our', 'text', 'mining', 'class', '!']
word_tokenize와는 달리 WordPunctTokenizer는 It’s를 It, ‘, s로 토큰을 분리하는 것을 볼 수 있다.
이는 두 토크나이저가 서로 다른 알고리즘으로 구현되었기 때문이다. 따라서 사용자는 토크나이저의 특성을 파악하고 자신의 목적에 맞는 토크나이저를 선택할 필요가 있다.
이제 word_tokenize를 한글에도 사용할 수 있는지 확인하자.
#단어 토큰화 : word_tokenize 한글 사용
print(word_tokenize(para_kor))
✨ 실행결과
['안녕하세요', ',', '여러분', '.', '만나서', '반갑습니다', '.', '이제', '텍스트마이닝', '클래스를', '시작해봅시다', '!']
한글을 대상으로 하는 토큰화는 엄밀하게 말하자면 의미를 가지는 최소 단위, 즉 형태소로 텍스트를 분리해야 한다. 그런데 한국어에서는 의미를 이루는 최소 단위가 공백 없이 붙어 있는 경우가 많아서 공백을 이용한 분리만으로는 부족하게 느껴질 수 있다.
3) 정규표현식을 이용한 토큰화
정규표현식을 사용하면 NLTK를 사용하지 않고도 다양한 조건에 따라 토큰화할 수 있다. 다만 정규표현식을 알아야 한다는 점에서 진입장벽이 있다.
정규표현식은 아래 사이트를 통해 연습할 수 있다.
RegExr: Learn, Build, & Test RegEx
RegExr is an online tool to learn, build, & test Regular Expressions (RegEx / RegExp).
regexr.com
NLTK 에서는 정규표현식을 사용하는 토크나이저를 아래와 같이 RegexpTokenizer로 제공한다.
from nltk.tokenize import RegexpTokenizer
#regular expression(정규식)을 이용한 tokenizer
#단어 단위로 tokenize \w : 문자나 숫자를 의미. 즉, 문자나 숫자 혹은 '가 반복되는 것을 찾아냄
tokenizer = RegexpTokenizer("[\w']+")
#can't 를 하나의 단어로 인식
print(tokenizer.tokenize("Sorry, I can't go there."))
✨ 실행결과
['Sorry', 'I', "can't", 'go', 'there']
⛄ 노이즈와 불용어 제거
정규표현식을 이용한 토큰화 과정에서 특수문자와 같은 불필요한 문자들 혹은 노이즈가 삭제되었다.
여기에 더해 불용어를 제거해야 하는데, 불용어는 의미 없는 특수문자 등과는 별로도, 실제 사용되는 단어이지만 분석에는 별 필요가 없는 단어들을 말한다. 보통 불용어는 빈도가 너무 적거나 혹은 반대로 빈도가 너무 많아서 별 필요가 없는 단어들이다.
NLTK에서는 stopwords라는 라이브러리를 이용해 언어별 불용어 사전을 제공한다.
#일반적으로 분석 대상이 아닌 단어들
from nltk.corpus import stopwords
#반복이 되지 않도록 set으로 변환
english_stops = set(stopwords.words('english'))
text1 = "Sorry, I couldn't go to movie yesterday."
tokenizer = RegexpTokenizer("[\w']+")
# word_tokenize 로 토큰화
tokens = tokenizer.tokenize(text1.lower())
# stopwords 를 제외한 단어들만으로 list를 생성
result = [word for word in tokens if word not in english_stops]
print(result)
✨ 실행결과
['sorry', 'go', 'movie', 'yesterday']
파이썬 set 함수
set은 수학에서 이야기하는 집합과 비슷합니다.순서가 없고, 집합안에서는 unique한 값을 가집니다.
list나 dict의 경우 대괄호나 중괄호로 선언할 수 있었습니다만, set은 dict타입과 동일한 중괄호를 사용하므로, 중괄호만으로는 생성할 수 없습니다.set 생성자를 이용합니다.
출처 : 파이썬 - 기본을 갈고 닦자! (위키독스) https://wikidocs.net/16044
만약 자신만의 불용어 사전을 만들어서 사용하고 싶다면 파이썬 리스트로 쉽게 구현할 수 있다.
#자신만의 stopwords 를 만들고 이용
#한글 처리에서도 유용하게 사용할 수 있음
#나만의 stopword를 리스트로 정의
my_stopword = ['i', 'go', 'to']
result = [word for word in tokens if word not in my_stopword]
print(result)
✨ 실행결과
['sorry', "couldn't", 'movie', 'yesterday']
⛄ 정규화
정규화는 같은 의미를 가진 동일한 단어이면서 다른 형태로 쓰여진 단어들을 통일해 표준 단어로 만드는 작업을 말한다. 정규화는 방법에 따라 어간 추출과 표제어 추출로 나뉘어진다.
1. 어간 추출
어간 추출은 “어형이 변형된 단어로부터 접사 등을 제거하고 그 단어의 어간을 분리해 내는 작업”을 말한다.
어형은 단어의 형태를 의미하고, 어간(stem)은 어형변화에서 변화하지 않는 부분을 말한다.
영어에 대한 어간 추출 알고리즘으로는 포터 스테머(Porter Stemmer), 랭카스터 스테머(Lancaster Stemmer) 등이 유명하다.
1) 포터 스테머
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
print(stemmer.stem('cooking'), stemmer.stem('cookery'), stemmer.stem('cookbooks'))
✨ 실행결과
cook cookeri cookbook
스테머 알고리즘은 단어가 변형되는 규칙을 이용해 원형을 찾으므로 그 결과가 항상 사전에 있는 올바른 단어가 되지는 않는다.
중요한 점은 포터 스테머를 쓰면 모든 단어가 같은 규칙에 따라 변환된다.
다음은 토큰화와 결합해 어간 추출을 하는 예시이다.
# 토큰화와 결합해 어간 추출
from nltk.tokenize import word_tokenize
para = "Hello everyone. It's good to see you. Let's start our text mining class!"
# 토큰화 실행
tokens = word_tokenize(para)
print(tokens)
# 모든 토큰에 대해 스테밍 실행
result = [stemmer.stem(token) for token in tokens]
print(result)
✨ 실행결과
['Hello', 'everyone', '.', 'It', "'s", 'good', 'to', 'see', 'you', '.', 'Let', "'s", 'start', 'our', 'text', 'mining', 'class', '!']
['hello', 'everyon', '.', 'it', "'s", 'good', 'to', 'see', 'you', '.', 'let', "'s", 'start', 'our', 'text', 'mine', 'class', '!']
2) 랭카스터 스테머
from nltk.stem import LancasterStemmer
stemmer = LancasterStemmer()
print(stemmer.stem('cooking'), stemmer.stem('cookery'), stemmer.stem('cookbooks'))
✨ 실행결과
cook cookery cookbook
어떤 스테머를 선택할지는 둘 다 수행해서 최종결과를 비교해 보면 결정할 수 있다.
분석의 목적이나 대상에 따라 더 좋은 성능을 보이는 스테머가 달라질 수 있기 때문이다.
2. 표제어 추출
표제어 추출(Lemmatization)은 lemma로 변환한다는 뜻이고 lemma는 우리말로 ‘단어의 기본형’으로 변역된다.
즉, 표제어 추출은 주어진 단어를 기본형으로 변환하는 것을 의미한다.
NLTK의 WordNetLemmatizer 로 표제어 추출하기
# NLTk의 WordNetLemmatizer 사용
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize('cooking'))
#품사 지정
print(lemmatizer.lemmatize('cooking', pos = 'v'))
print(lemmatizer.lemmatize('cookkery'))
print(lemmatizer.lemmatize('cookbooks'))
✨ 실행결과
cooking cook cookkery cookbook
위 실행 결과를 보면 문장이 있는 단어의 정확한 기본형을 알기 위해서는 품사 정보가 필요할 수 있다.
⛄ 품사 태깅
품사
는 “명사, 대명사, 수사, 조사, 동사, 형용사, 관형사, 부사, 감탄사와 같이 공통된 성질을 지닌 낱말끼리 모아 놓은 낱말의 갈래”를 말한다. — 네이버 지식백과 초등국어 개념사전
여기서 낱말이란 ‘뜻을 가지고 홀로 쓰일 수 있는 말의 가장 작은 단위’라는 뜻이다. 예를 들어 ‘맨손’은 ‘맨’과 ‘손’의 두 형태소로 이루어진 단어인데, ‘맨’은 자립성이 없어 독립적으로 쓰지 못해 낱말이 아니다.
다음은 한국어 품사와 품사에 대한 설명을 표로 정리한 것이다.
| 품사명 | 설명 |
| 명사 | 사물, 개념, 인물 등을 가리키는 낱말 |
| 대명사 | 이름 대신 사용되는 낱말 |
| 수사 | 수량이나 순서를 가리키는 낱말 |
| 조사 | 말의 어감을 부드럽게 하거나 문장의 어순을 정확하게 하기 위해 쓰이는 낱말 |
| 동사 | 행동, 작용, 상태 등을 나타내는 낱말 |
| 형용사 | 사물의 성질, 상태 등을 나타내는 낱말 |
| 관형사 | 체언을 꾸며 주는 낱말 |
| 부사 | 주로 용언을 꾸며 주는 낱말 |
| 감탄사 | 놀람, 기쁨, 슬픔 등의 감정을 나타내는 낱말 |
품사 태깅(Part-of_Speech Tagging)은 형태소에 대해 품사를 파악해 부착(tagging)하는 작업을 말한다.
1. NLTK를 활용한 품사 태깅
영어로 된 텍스트에 대해 품사 태깅을 하고자 한다면 NLTK를 쓰는 것이 가장 편하다.
nltk.pos_tag()은 토큰화된 결과에 대해 품사를 태깅해 (단어, 품사)로 구성된 튜플의 리스트로 품사 태깅 결과를 반환해 준다.
import nltk
from nltk.tokenize import word_tokenize
tokens = word_tokenize("Hello everyone. It's good to see you. Let's start our text mining class!")
print(nltk.pos_tag(tokens))
✨ 실행결과
[('Hello', 'NNP'), ('everyone', 'NN'), ('.', '.'), ('It', 'PRP'), ("'s", 'VBZ'), ('good', 'JJ'), ('to', 'TO'), ('see', 'VB'), ('you', 'PRP'), ('.', '.'), ('Let', 'VB'), ("'s", 'POS'), ('start', 'VB'), ('our', 'PRP$'), ('text', 'NN'), ('mining', 'NN'), ('class', 'NN'), ('!', '.')]
품사의 약어를 잘 모를 경우에는 nltk.help.upenn_tagset() 를 사용해 품사 약어의 의미와 설명을 볼 수 있다.
nltk.help.upenn_tagset('CC')
✨ 실행결과
CC: conjunction, coordinating & 'n and both but either et for less minus neither nor or plus so therefore times v. versus vs. whether yet
✔ 원하는 품사의 단어들만 추출
상황에 따라 명사만 필요하거나, 특정 품사들만 사용할 때에는 아래와 같은 방법으로 원하는 품사들을 골라낼 수 있다.
# 원하는 품사의 단어들만 추출
my_tag_set = ['NN', 'VB', 'JJ']
my_words = [word for word, tag in nltk.pos_tag(tokens) if tag in my_tag_set]
print(my_words)
✨ 실행결과
['everyone', 'good', 'see', 'Let', 'start', 'text', 'mining', 'class']
✔ 단어에 품사 정보를 추가해 구분
동음이의어를 처리하거나 품사를 이용해 단어를 더 정확하게 구분하고 싶다면, 다음과 같이 단어 뒤에 품사 태그를 붙여 사욜할 수 있다.
# 단어에 품사 정보를 추가해 구분
words_with_tag = ['/'.join(item) for item in nltk.pos_tag(tokens)]
print(words_with_tag)
✨ 실행결과
['Hello/NNP', 'everyone/NN', './.', 'It/PRP', "'s/VBZ", 'good/JJ', 'to/TO', 'see/VB', 'you/PRP', './.', 'Let/VB', "'s/POS", 'start/VB', 'our/PRP$', 'text/NN', 'mining/NN', 'class/NN', '!/.']
2. 한글 형태소 분석과 품사 태깅
NLTK로는 한국어 문서에 대해서 품사 태깅을 할 수 없다.
따라서 다른 라이브러리인 KoNLPy를 사용해야 한다. KoNLPy는 Hannanum, Kkma, Komoran, Twitter, Mecab 이렇게 다섯 종의 형태소 분석기를 제공한다.
!pip install konlpy
위 코드를 실행해서 KoNLPy 를 설치해준다.
설치가 완료되면 KoNLPy가 제공하는 형태소 분석기 중에서 Twitter 클래스를 임포트해서 사용한다.
✔ morphs(phrase): 주어진 텍스트를 형태소 단위로 분리합니다.
✔ nouns(phrase): 주어진 텍스트를 형태소 단위로 분리해서 명사만을 반환합니다.
✔ pos(phrase): 주어진 텍스트를 형태소 단위로 분리하고, 각 형태소에 품사를 부착해 반환합니다.
sentence = '''절망의 반대가 희망은 아니다.
어두운 밤하늘에 별이 빛나듯
희망은 절망 속에 싹트는 거지
만약에 우리가 희망함이 적다면
그 누가 세상을 비출어줄까.
정희성, 희망 공부'''
from konlpy.tag import Okt
t = Okt()
print('형태소: ', t.morphs(sentence))
print()
print('명사: ', t.nouns(sentence))
print()
print('품사 태깅 결과: ', t.pos(sentence))
✨ 실행결과
형태소: ['절망', '의', '반대', '가', '희망', '은', '아니다', '.', '\n', '어', '두운', '밤하늘', '에', '별', '이', '빛나듯', '\n', '희망', '은', '절망', '속', '에', '싹트는', '거지', '\n', '만약', '에', '우리', '가', '희망', '함', '이', '적다면', '\n', '그', '누가', '세상', '을', '비출어줄까', '.', '\n', '정희성', ',', '희망', '공부']
명사: ['절망', '반대', '희망', '어', '두운', '밤하늘', '별', '희망', '절망', '속', '거지', '만약', '우리', '희망', '함', '그', '누가', '세상', '정희성', '희망', '공부']
품사 태깅 결과: [('절망', 'Noun'), ('의', 'Josa'), ('반대', 'Noun'), ('가', 'Josa'), ('희망', 'Noun'), ('은', 'Josa'), ('아니다', 'Adjective'), ('.', 'Punctuation'), ('\n', 'Foreign'), ('어', 'Noun'), ('두운', 'Noun'), ('밤하늘', 'Noun'), ('에', 'Josa'), ('별', 'Noun'), ('이', 'Josa'), ('빛나듯', 'Verb'), ('\n', 'Foreign'), ('희망', 'Noun'), ('은', 'Josa'), ('절망', 'Noun'), ('속', 'Noun'), ('에', 'Josa'), ('싹트는', 'Verb'), ('거지', 'Noun'), ('\n', 'Foreign'), ('만약', 'Noun'), ('에', 'Josa'), ('우리', 'Noun'), ('가', 'Josa'), ('희망', 'Noun'), ('함', 'Noun'), ('이', 'Josa'), ('적다면', 'Verb'), ('\n', 'Foreign'), ('그', 'Noun'), ('누가', 'Noun'), ('세상', 'Noun'), ('을', 'Josa'), ('비출어줄까', 'Verb'), ('.', 'Punctuation'), ('\n', 'Foreign'), ('정희성', 'Noun'), (',', 'Punctuation'), ('희망', 'Noun'), ('공부', 'Noun')]
출처: 고려대학교 컴퓨터 동아리 KUCC 2023 자연어처리 세션
'인공지능 > 자연어처리' 카테고리의 다른 글
| 그래프와 워드 클라우드 (0) | 2023.04.02 |
|---|---|
| 텍스트 마이닝 기초 (0) | 2023.04.01 |