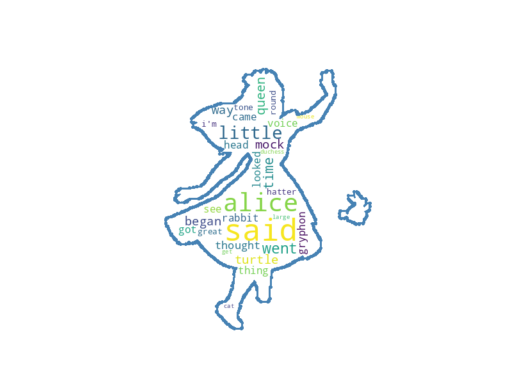
⛄ 단어 빈도 그래프 텍스트 분석에서 가장 단순하고 기본적인 아이디어는 하나 혹은 여러 개의 문서에서 가장 많이 사용된 단어를 파악하는 것으로, 이것만으로도 상당히 많은 정보를 얻을 수 있다. 단어 빈도 그래프를 그리려면 먼저 단어의 빈도를 구해야 한다. 이 작업을 하기 전 전처리 단계에서 앞서 배운 다양한 전처리 기법들을 활용한다. 데이터셋은 저작권이 만료된 영어 소설들을 제공하는 구텐베르크 프로젝트가 있는데, 여기서 루이스 캐럴의 이상한 나라의 앨리스 문서를 활용한다. import nltk nltk.download('gutenberg') from nltk.corpus import gutenberg # 파일 제목을 읽어온다. file_names = gutenberg.fileids() print(file..